Introduction
At November 29, TensorFlow 0.12 was released.
One of the functions is visualization of embedded representation. This makes it possible to analyze high dimensional data interactively.
The following is a visualization of MNIST. The following is just a image, but you can watch 3D animation in the official website.

In this article, I tried using Embedding Visualization through visualization of Word2vec. First, let’s install TensorFlow 0.12.
Installation
First, install TensorFlow 0.12. Please refer to the following pages for installation.
After installation, let’s start with learning model for visualization.
Learning Model
After cloning the repository, execute the following command to move it into the repository:
$ git clone https://github.com/tensorflow/tensorflow.git
$ cd tensorflow/models/embedding
To download training data and evaluation data, execute the following command:
$ wget http://mattmahoney.net/dc/text8.zip -O text8.zip
$ unzip text8.zip
$ wget https://storage.googleapis.com/google-code-archive-source/v2/code.google.com/word2vec/source-archive.zip
$ unzip -p source-archive.zip word2vec/trunk/questions-words.txt > questions-words.txt
$ rm source-archive.zip
We prepared data for learning so we can learn word vectors. Please execute the following command for learning model:
$ python word2vec_optimized.py --train_data=text8 --eval_data=questions-words.txt --save_path=/tmp/
Please wait for about 1 hour to learn.
Displaying Embedding Representation with TensorBoard
When learning is over, we display embedding representation. Please run TensorBoard by executing the following command:
$ tensorboard --logdir=/tmp/
After running tensorboard, access the specified address. After that, when you select the Embedding tab, the visualized vector is displayed.
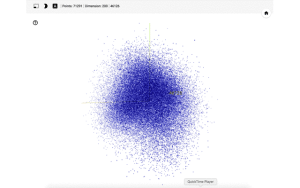
I think there are too many vocabularies to visualize.:-(
If nothing is displayed
When selecting the Embedding tab, nothing is displayed on the browser, and the following errors may be displayed on the console.
File "/Users/user_name/venv/lib/python3.4/site-packages/tensorflow/tensorboard/plugins/projector/plugin.py", line 139, in configs
run_path_pairs.append(('.', self.logdir))
AttributeError: 'dict_items' object has no attribute 'append'
In that case, please change line 139 of tensorflow/tensorboard/plugins/projector/plugin.py of installed TensorFlow as follows. Then restart TensorBoard.
- run_path_pairs.append(('.', self.logdir))
+ run_path_pairs = [('.', self.logdir)]
I will try various things
After selecting a certain node (word), when selecting “isolate 101 points”, it is displayed as follows.

This means that 100 words similar to the selected word are displayed. To measure similarity here, we can use cosine similarity and Euclidean distance. You can also increase or decrease the number of words to display by specifying neighbors.
You can use multiple algorithms for visualization.

PCA is the default, but you can also use T-SNE and CUSTOM. In the following images, it is displayed in 3D, but it can also be displayed in 2D.
Conclusion
It seems to be more interesting if you assign words as labels. Please let me know if you know the methods.
Reference
- https://github.com/tensorflow/tensorflow/tree/r0.12/tensorflow/models/embedding
- https://github.com/tensorflow/tensorflow/blob/r0.12/tensorflow/models/embedding/word2vec_optimized.py
- https://github.com/tensorflow/tensorflow/pull/5937