You may be familiar with Word2vec (Mikolov et al., 2013). Word2vec allows you to add and subtract words as though they are capturing the meaning of a word. For example, it is famous that Queen is calculated by subtracting Man from King and adding Woman (King — Man + Woman = Queen).

from https://www.tensorflow.org/get_started/embedding_viz
Distributed representations, also known as word embeddings, represent words as high-dimensional vectors (typically around 200 dimensions). These vectors capture various semantic and syntactic features of words, enabling meaningful mathematical operations between them. For example, adding and subtracting these vectors can reveal semantic relationships between words.
The importance of distributed representations in modern Natural Language Processing (NLP) cannot be overstated. As neural network-based models have become prevalent in NLP, these word embeddings serve as crucial input features that significantly impact model performance.
This article explores three key aspects of distributed representations:
- A brief overview of how they work
- Their fundamental importance to modern NLP
- Current challenges and limitations in their implementation
What is Distributed Representation of Words?
In this section, I will explain distributed representation of words for the purpose of understanding it. For comparison, I will also explain one-hot representation of words. After explaining one-hot representation and its problem, I will explain distributed representation and its merits.
One-hot Representation
One-hot representation is a simple method for encoding words as vectors. In this approach, each word is represented as a vector where only one element is 1, and all other elements are 0. The length of the vector equals the size of the vocabulary, with each position corresponding to a specific word. This creates a binary encoding system where the single ‘1’ indicates the presence of that specific word, while all ‘0’s indicate the absence of other words in the vocabulary.
Let’s say, for example, we represent the word “python” as one-hot representation. Here, the vocabulary which is a set of words is five words(nlp, python, word, ruby, one-hot). Then the following vector expresses the word “python”:

Although one-hot encoding is simple, it has significant drawbacks—chiefly, it doesn’t allow for meaningful arithmetic operations between vectors.
For example, if we calculate the similarity between words using the inner (dot) product, the result is unhelpful. In one-hot encoding, different words have a ‘1’ in different positions and ‘0’s elsewhere, so the dot product of any two distinct word vectors is zero. This provides no useful information about the similarity between words..

Another weak point is the vector tend to become very high dimension. Since one dimension is assigned to one word, as the number of vocabularies increases, it becomes very high dimension.
Distributed Representation
Distributed representation, on the other hand, is a representation of a word as a low-dimensional real-valued vector. It is often expressed from about 50 to 300 dimensions. For example, the above words can be expressed as distributed representation as follows:

By using distributed representation, you can solve the problems that one-hot representation has. For example, you can calculate the similarity between words by vector operation. Looking at the above vector, the similarity between “python” and “ruby” seems to be higher than the similarity between “python” and “word”. Also, even if the number of vocabulary increases, you do not increase the number of dimensions of each word.
Why is Distributed Representation of Word Important?
In this section, I will explain the importance of distributed representation of words in NLP. First, I will explain input to NLP tasks. Then, I will talk about using distributed representation as input. Finally, I will explain distributed representation affecting task performance.
In many NLP tasks, input is given as word sequences. For example, document classification treats input as the set of words contained in the document. Part-of-speech tagging and named entity recognition treats input as separated word sequences. The following image shows input and output in NLP tasks.
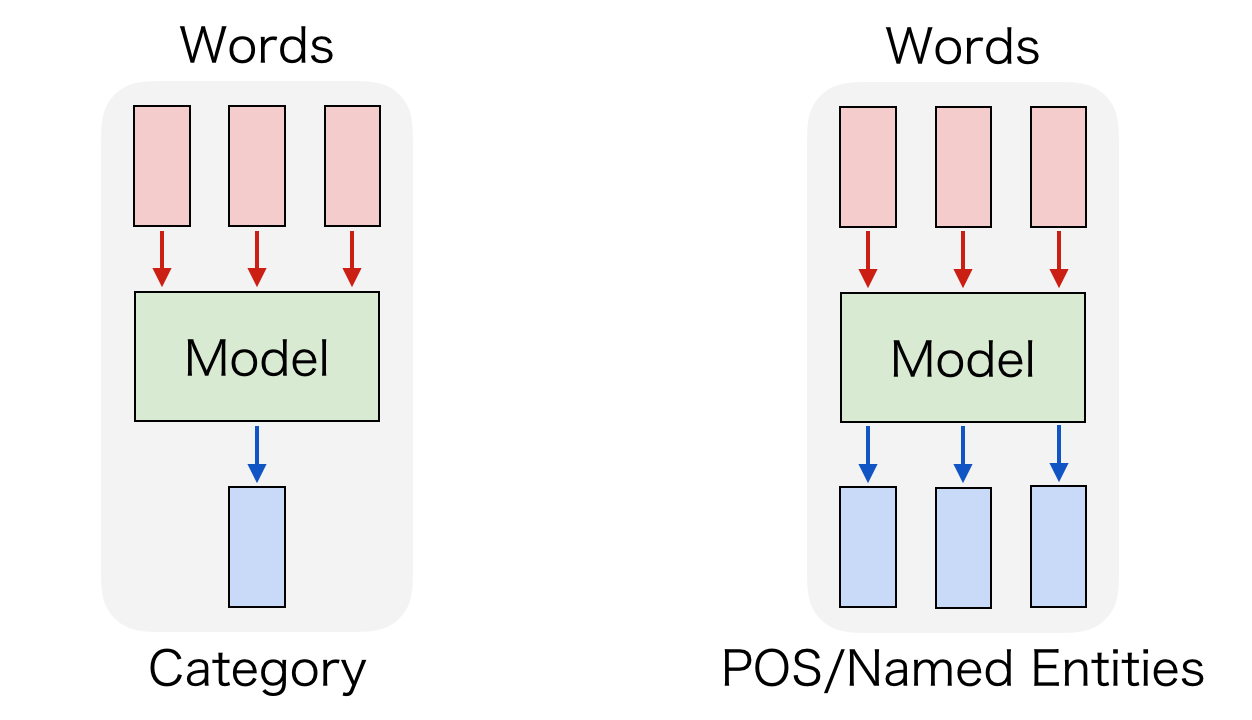

In recent NLP, neural networks are often used, input is given as word sequences. Input to RNN, which is often used in NLP, is word sequences, and input to CNN, which has recently been receiving attention in NLP, is also often word sequences. The following image shows input of CNN is distributed representation.

Actually, in many cases, we use distributed representation of word as input to these neural networks. It is based on the expectation that task performance will improve if you use representation that better understand the meaning of word as input. It is also possible to use the distributed representation learned with a large amount of unlabeled data as the initial value of the network and tune it with a small amount of labeled data.
This distributed representation is important because it affects task performance. It has also been reported that the performance improves compared with the case without using distributed representation[2]. In this way, distributed representation is often used as an input for many tasks, and it affects performance. Thus, it is important.
Problems of Distributed Representation
Distributed representation of word is not a silver bullet in NLP. As a result of many studies, we know that there are various problems. Here I will choose two of them and introduce it.
Problem 1: Performance fall short of expectation
The first problem is that when we use distributed representation in actual task (document classification etc.), the performance often fall short of expectation. In the first place, how distributed representation of word is evaluated is often evaluated by the degree of correlation with the evaluation set of word similarity created by humans (Schnabel, Tobias, et al, 2015). In other words, using the distributed representation obtained in the model that can produce results that correlate with the human evaluation will not improve performance even if it is used for the actual task.
The reason is that most evaluation datasets do not distinguish between word similarity and relatedness. The similarity and relatedness of words is, for example, that (male, man) is similar, that (computer, keyboard) is related, but dissimilar. It is reported that a positive correlation of performance with the actual task is seen in the distinguished dataset(Chiu, Billy, Anna Korhonen, and Sampo Pyysalo, 2016).
Therefore, it is now attempted to create an evaluation dataset that correlates with the actual task(Oded Avraham, Yoav Goldberg, 2016). In this paper, they are attempting to solve two problems in existing datasets (First, they do not distinguish between similarity and relatedness of words, second, annotation scores vary among evaluators).
In addition to creating an evaluation dataset, research is being conducted to evaluate distributed representation so that actual tasks can be easily evaluated (Nayak, Neha, Gabor Angeli, and Christopher D. Manning, 2016). It is expected that this will make it possible to easily verify whether the learned distributed representation is effective for tasks close to the tasks that you actually want to do.
Personally, I hope that the currently ignored models will be reevaluated by evaluating with new datasets or tasks.
Problem 2: Word Ambiguity
The second problem is that the current distributed representation does not take word ambiguity into account. Words have various meanings. For example, the word “bank” has the meaning of “sloping land” in addition to the meaning of “a financial institution”. In this way, there is a limit to represent word as one vector without considering word ambiguity.
To solve this problem, several methods have been proposed[5][6][7][8]. In those methods, each word has multiple representations. For example, SENSEEMBED learns representations at word sense level. As a result of learning representations for each word sense, it is reported that performance in word similarity evaluation improved.
More detail
In the following repositories, I have listed information on distributed representation of words and sentences, pre-trained vectors, and implementations.
Your star encourage me m(_ _)m
Conclusion
Distributed representation of word is an interesting field that is actively studied. I hope this article will help you understand.
I have been posting information on NLP and machine learning on Twitter.
If you are interested in these fields, Please Follow Me!
@Hironsan
References
- Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
- Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. “Glove: Global Vectors for Word Representation.” EMNLP. Vol. 14. 2014.
- Schnabel, Tobias, et al. “Evaluation methods for unsupervised word embeddings.” EMNLP. 2015.
- Chiu, Billy, Anna Korhonen, and Sampo Pyysalo. “Intrinsic evaluation of word vectors fails to predict extrinsic performance.” ACL 2016 (2016): 1.
- Oded Avraham, Yoav Goldberg. “Improving Reliability of Word Similarity Evaluation by Redesigning Annotation Task and Performance Measure.” arXiv preprint arXiv:1611.03641 (2016).
- Nayak, Neha, Gabor Angeli, and Christopher D. Manning. “Evaluating Word Embeddings Using a Representative Suite of Practical Tasks.” ACL 2016 (2016): 19.
- Trask, Andrew, Phil Michalak, and John Liu. “sense2vec-A fast and accurate method for word sense disambiguation in neural word embeddings.” arXiv preprint arXiv:1511.06388 (2015).
- Iacobacci, I., Pilehvar, M. T., & Navigli, R. (2015). SensEmbed: Learning Sense Embeddings for Word and Relational Similarity. In ACL (1) (pp. 95-105).
- Reisinger, Joseph, and Raymond J. Mooney. “Multi-prototype vector-space models of word meaning.” Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010.
- Huang, Eric H., et al. “Improving word representations via global context and multiple word prototypes.” Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Association for Computational Linguistics, 2012.